
by: SEO Strategist
Ashot Nanayan
Updated August 10, 2025
21 min read
WhatsApp
 (+1) 818 355 1889
(+1) 818 355 1889
WhatsApp
(+1) 818 355 1889
WhatsApp
(+1) 818 355 1889
WhatsApp
(+1) 818 355 1889
WhatsApp
(+1) 818 355 1889
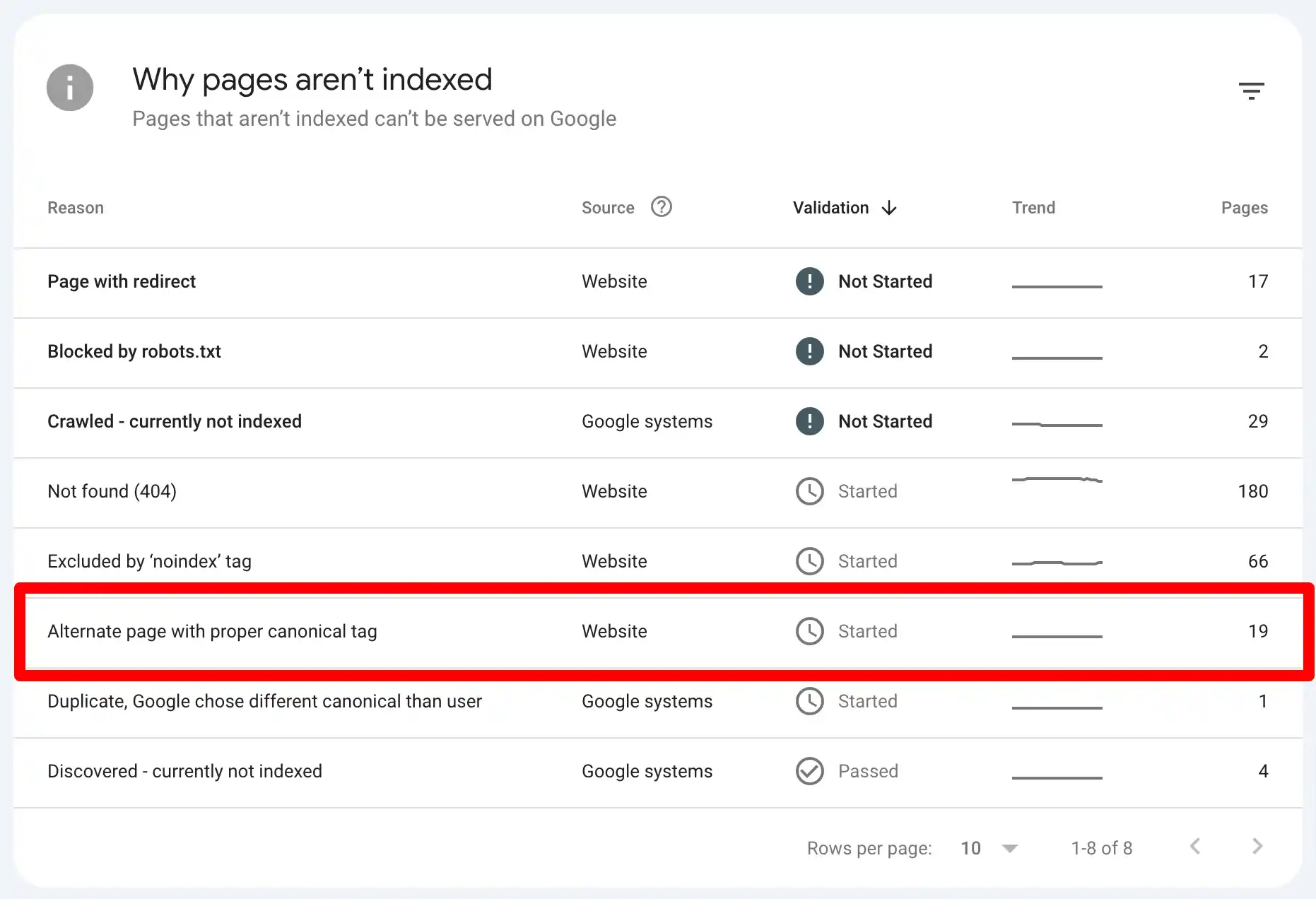
Let me guess, you logged into Google Search Console, ran a quick check on your indexing report, and there it was: ‘Alternate Page with Proper Canonical Tag’. If you’re anything like most website owners or SEO pros, your first thought might have been, “Is this a problem? Do I need to fix it? And why does it even happen?”
The issue is one of the most common indexing problems in GSC, yet most of the advice available online only provides superficial insights, repeats outdated best practices, or leaves you with more questions than answers.
Seeing your GSC report flagged with indexing issues can feel like discovering an error message on your car dashboard. You want clarity, you want actionable solutions, and most importantly, you want to make sure that your site’s visibility isn’t quietly suffering because of these alternate canonical tags.
I’m not just going to cover the basics or give you surface-level fixes. We’ll break this down step-by-step. I’ll show you:
In this guide, we’re going straight to the point. I’ll explain what this issue means (without empty promises), why it happens, and most importantly, how to fix it step by step. No jargon overload, no blurry advice.
If you’re ready to clean up your site’s indexing signals and keep Google happy, let’s dive in.

A canonical URL is an HTML tag (rel=”canonical”) used to tell search engines which version of a page is the preferred or “master” version when there are duplicate or similar pages. It’s essentially a signal to search engines saying, “This is the main version of this content; please focus on this one.”
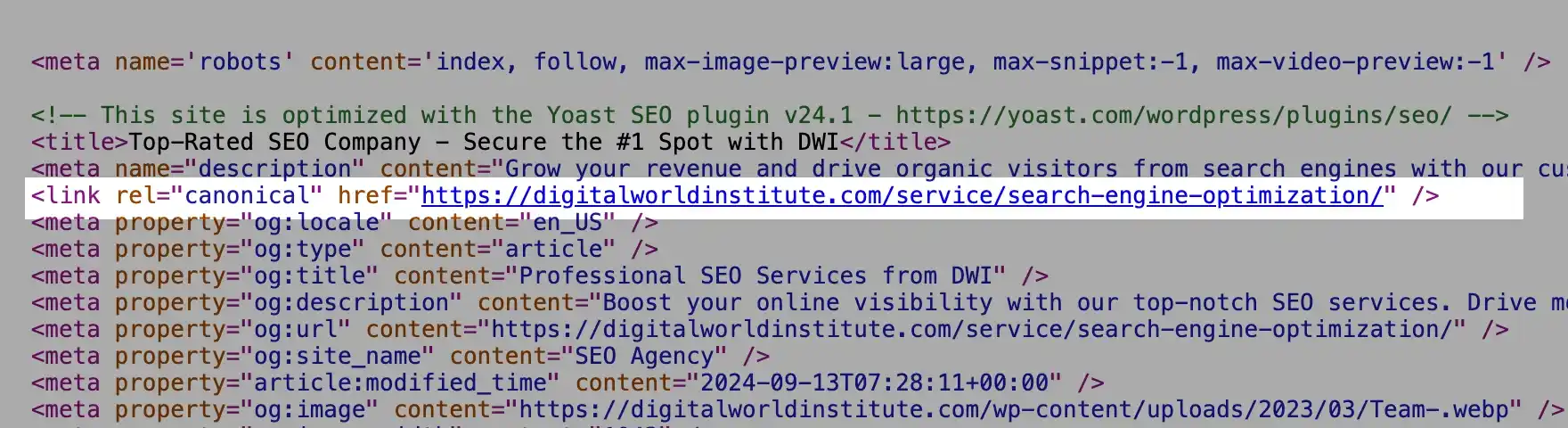
For example, if you have the same blog post accessible at /blog/post and /blog/post?ref=123, the canonical tag tells search engines which one should be considered the primary URL.
Canonical tags prevent duplicate content issues that can confuse search engines and decrease your ranking potential. Without a canonical tag, search engines might index multiple versions of the same content, spreading out link equity and making it harder for any single version to rank well.

Google treats the canonical tag as a strong hint rather than an absolute directive. If Google agrees that the specified canonical URL is the most relevant version, it will consolidate ranking signals and display that URL in search results.
However, if Google detects inconsistencies, like conflicting canonical tags or sitemap errors, it might ignore the tag and choose a canonical URL on its own.
Let’s break down the key conditions with simple explanations and sample code.
A self-referencing canonical tag points to the same URL as the current page. This is the best practice for standard pages to make sure search engines understand the URL as the authoritative version.
When to use it:
Sample Code:
The product page https://www.example.com/product-page contains a self-canonical pointing to itself. This eliminates confusion caused by URL parameters like ?ref=affiliate123.
A canonicalized page points to another URL as the preferred version. This is commonly used when multiple pages have similar content, and you want to combine their ranking signals.
When to use it:
Sample Code:
On https://www.example.com/product-page-red, you might see:
Example Scenario:
You have two product URLs:
If both have nearly identical content, you canonicalize them to https://www.example.com/product-page to avoid duplicate content issues.
When there’s no canonical tag, search engines must decide on their own which version of the page to rank. This often leads to duplicate content issues and inconsistent indexing.
When it happens:
Sample Code:
(No <link rel=”canonical”> tag present in the <head> section.)
Example Scenario:
Without a canonical tag, search engines might index both URLs as separate pages creating duplicate content problems.
If you’ve come across the ‘Alternate Page with Proper Canonical Tag’ warning in Google Search Console, you might be wondering what it means and if it’s affecting your SEO. Don’t worry, it’s not always a red flag. Let’s dive into the key reasons this issue arises and whether it requires your attention.
One common reason behind the ‘Alternate Page with Proper Canonical Tag’ Issue is the WWW vs. Non-WWW version conflict.
Your website can technically exist in two formats:
https://www.example.com
https://example.com
Of course, they might look identical to most users, but search engines treat these as two separate websites unless they are properly configured. If both versions are accessible and indexable without redirects or canonical tags, Google may get confused about which version to prioritize.
For example:
If your canonical tag points to the non-WWW version but the WWW version is also indexed, Google will treat one as an “alternate” version of the other.
a. Manual Check:
b. Use Google Search Operators:
c. Check in Google Search Console:
d. Use an online WWW redirect checker
a. Choose Your Preferred Version:
b. Implement 301 Redirects:
Example for .htaccess (Apache):
Example for nginx.conf (Nginx):
⚠️ Things to Double-Check:
Make sure your SSL certificates are properly installed and referenced (ssl_certificate, ssl_certificate_key).
Verify that the DNS settings for www.example.com and example.com are correctly pointed to your server.
c. Set the Preferred Domain in Google Search Console:
d. Update Canonical Tags:
Make sure all internal links consistently point to the preferred version (WWW or non-WWW). If possible, reach out to high-authority websites linking to the incorrect version and ask them to update their links. Make sure your XML sitemap only includes URLs from your preferred domain version.
After implementing these steps use a tool like Screaming Frog or Ahrefs Site Audit to make sure all redirects are working correctly and monitor GSC regularly to see if the “Alternate Page with Proper Canonical Tag” warnings decrease.
Pagination occurs when content is split across multiple pages, often seen in URLs like /blog/page/2/ or /products?page=3. These pages usually share a significant amount of content structure, such as headers, titles, and meta descriptions, leading Google to see them as duplicate or near-duplicate content.

This creates a problem because Google might prioritize the first page of your pagination series and ignore valuable content hidden deeper in the paginated set.
Go to Indexing > Pages in GSC. Look for entries marked as “Alternate Page with Proper Canonical Tag.” Review the listed URLs to see if they include pagination patterns (/page/2/, ?page=3).
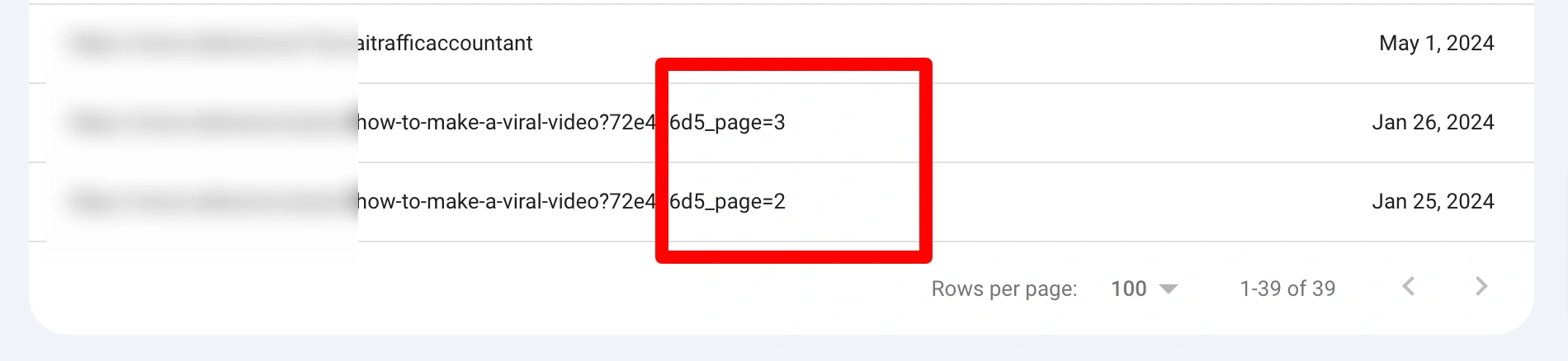
Use the URL Inspection Tool in GSC to check if paginated URLs have a canonical tag pointing to the main page (/blog/ or /products/).
If every paginated page points to the main page as canonical, it could prevent Google from properly indexing deeper content.
Check if rel=“prev” and rel=“next” tags are properly implemented (though Google no longer officially uses them, they still help for clarity). Make sure paginated pages have internal links pointing to deeper content instead of looping back to the main archive page.
Instead of setting every paginated page to canonicalize to /blog/ or /products/, allow each paginated URL (/blog/page/2/, /blog/page/3/) to self-canonicalize.
This tells Google that each page is intentionally part of a sequence and deserves individual indexing.
Avoid infinite scrolling without a “view all” option, as it can prevent crawlers from accessing deeper content. If your content can reasonably fit on a single page, offer a “View All” option. Canonicalize paginated URLs to the “View All” version.
In some cases, if deeper paginated content doesn’t hold unique value, you can set them to “noindex, follow” in the meta robots tag. However, be careful, though, as this can cause orphaned pages if you don’t handle it properly.
Duplicate content occurs when multiple URLs display identical or highly similar content, causing search engines to struggle to determine which version to rank in search results. In response, Google may automatically choose a canonical version; the URL it considers the “main” one, and label the others as “Alternate Page with Proper Canonical Tag” in Google Search Console (GSC).
This issue is common on eCommerce websites, where product pages can be accessed through multiple URLs due to variations like sorting filters, category paths, or tracking parameters. For instance:
Yep, these URLs point to the same content but Google may decide one is the primary (canonical) version and mark the others as alternates.
Google Search Console (GSC):
Navigate to the Indexing > Pages report. Look for pages marked as “Alternate Page with Proper Canonical Tag.” Review the list to identify patterns or problematic URLs.
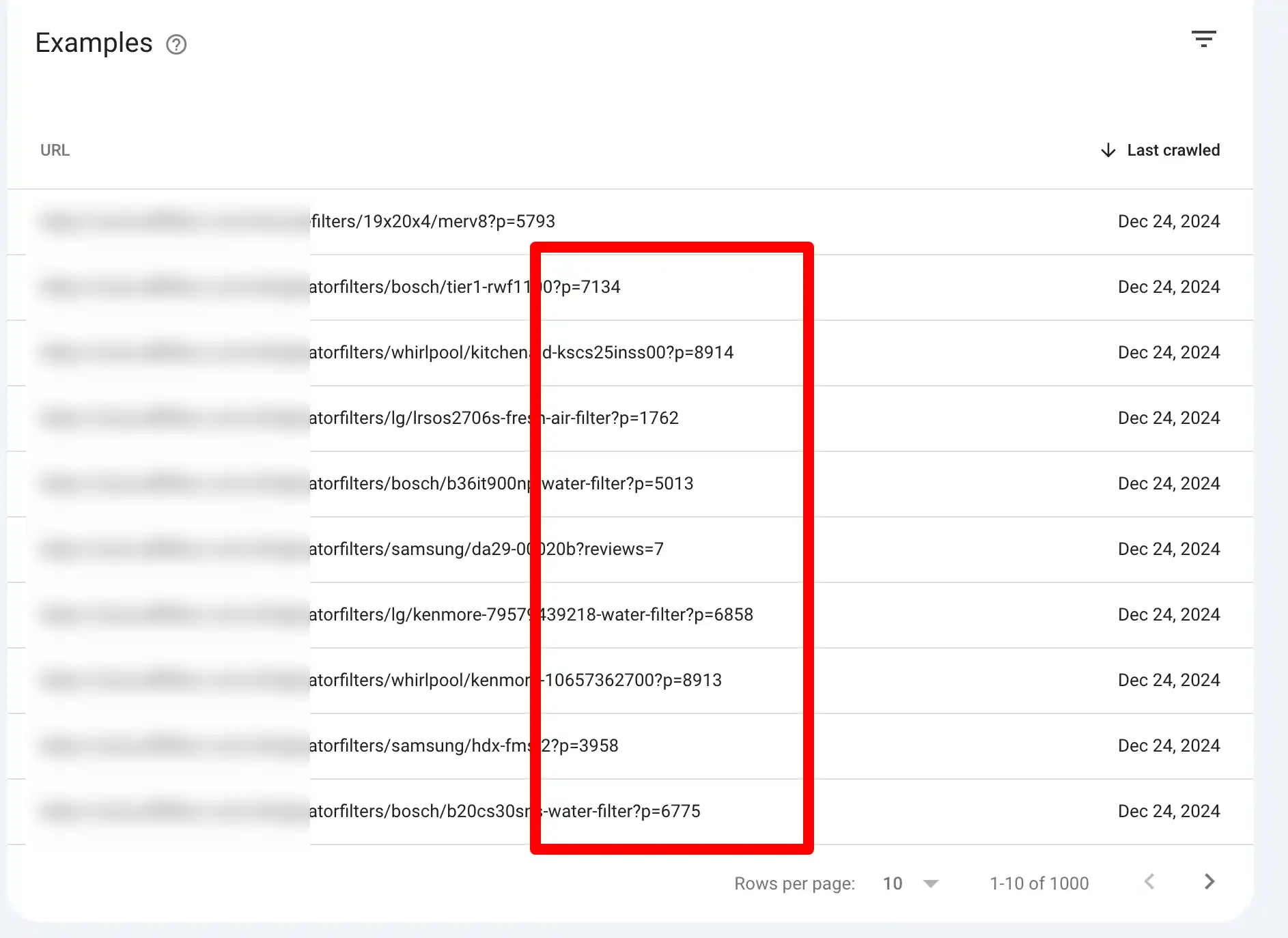
You can also use site:yourdomain.com in Google with fragments of duplicate content or specific URLs, then compare indexed URLs to see if duplicates are appearing.
You can use canonical tags to make sure each duplicate URL points to the preferred canonical version using the <link rel=”canonical” href=”https://example.com/preferred-page”/> tag in the <head> section.If duplicates serve no real purpose, set up 301 redirects to the primary URL. For product variations (e.g., colors or sizes), use canonical tags to point all variants to a single product page, or implement parameter-based rules.
If your website has both HTTP (non-secure) and HTTPS (secure) versions accessible, search engines may view them as two separate URLs, even if they display the same content.
For example:
In an ideal setup, all HTTP traffic should redirect to HTTPS versions using 301 redirects, and the canonical tag on each page should point explicitly to the preferred HTTPS version. However, if these steps aren’t properly implemented, Google might see both versions as valid, index them separately, and then flag the HTTP version as an alternate page with a proper canonical tag pointing to the HTTPS version.
One of the common reasons Google Search Console (GSC) might flag a page as an “Alternate Page with Proper Canonical Tag” is due to trailing slash inconsistencies in your website’s URLs. In simple terms, a trailing slash refers to the “/” at the end of a URL.
For example:
These URLs may seem exactly the same to users. However, search engines treat them as two distinct URLs. If both variations exist and are accessible, Google must decide which one is the “canonical” version—the preferred URL to display in search results.
When this inconsistency isn’t handled properly, both versions may end up being indexed or flagged in GSC. For instance, if /page/ is set as the canonical version but /page is also accessible, Google might mark /page as an alternate version with the canonical pointing to /page/.
The default settings, plugins, or even themes of famous content management systems (CMS) like WordPress, Shopify, or Wix can unintentionally create duplicate or alternate versions of your pages. This often happens when the CMS automatically generates paginated URLs, tag pages, or category archives without proper canonicalization settings.
For example, a blog post might exist at multiple URLs:
These URLs technically point to the same content, but the CMS might not set the canonical tag correctly, or the theme might override global settings, leading Google to flag them as “Alternate Page with Proper Canonical Tag.”
In some cases, poorly coded themes can also generate unnecessary URL parameters or duplicate content paths. For instance, search or filter functionalities on eCommerce websites can produce multiple variations of the same product page (?color=red, ?size=medium) without pointing them to the primary version with a canonical tag.
Plugins you use for SEO or caching can further complicate things. Sometimes, two plugins might conflict with each other, causing incorrect canonical URLs to be applied across pages. Additionally, CMS themes with built-in SEO settings can conflict with plugins like Yoast SEO or Rank Math, leading to inconsistencies in canonical tags.
Start with the HTML source code of the affected pages. Open the page in your browser, right-click, and select “View Page Source” or press Ctrl+U. Search for the canonical tag using Ctrl+F and type rel=”canonical”. The tag should look like this:
Make sure:
Tools for HTML Inspection:
Sometimes, canonical tags are included in the HTTP headers rather than the HTML source. To check this:
Use a tool like cURL or an online header checker tool like httpstatus.io.
Look for the canonical header in the HTTP response, which will appear as:
Link: <https://example.com/primary-page/>; rel=”canonical”
If the canonical tag is in both the HTML and HTTP headers but points to different URLs, search engines may receive conflicting signals, which could result in indexing the wrong page.
Next, head over to Google Search Console (GSC) under Indexing > Pages and look for the “Alternate Page with Proper Canonical Tag” issue. Click on the affected URLs and check:
If they differ, you’ll need to revise your implementation. Additionally, perform a site search query (site:example.com/page) in Google to see if the correct canonical version is appearing in the search results.
During the audit, check for scenarios like:
Remember, sometimes, deployment errors cause canonical mismatches in live environments. Use tools like Google’s URL Inspection Tool in Search Console or Screaming Frog’s “View Source Live” option to check canonical tags in real time.
If the issue occurs on paginated pages (e.g., /blog/page/2/), make sure canonical tags are set correctly.
I know it’s easy to assume that adding a single line of code will solve everything. But in reality, implementing canonical URLs correctly is one of the more nuanced aspects of SEO. Now, I’ll share advanced techniques to address canonicalization challenges, especially in complex scenarios
Multi-language websites often struggle with canonicalization because of the overlap between hreflang and canonical tags. Each language version should have a self-referencing canonical tag, while the hreflang attribute signals alternate versions for different regions or languages.
For example:
A common mistake is pointing all language versions to a single canonical URL (e.g., /en/page/). This tells Google to ignore alternate versions and index only the English version. So, always confirm that hreflang tags and canonical tags align properly.
If your website relies on JavaScript frameworks (e.g., React, Angular, or Vue), canonical tags can sometimes fail to render properly for search engines. While Google claims it can process JavaScript effectively, there’s often a gap between what’s promised and what’s indexed.
To avoid this:
For mission-critical pages, manual verification with tools like View Rendered Source Chrome extension can confirm proper rendering.
Content syndication (e.g., republishing your blog posts on third-party platforms) often introduces canonical tag confusion. If multiple websites publish the same content without proper canonicalization, Google may struggle to determine the original source.
We’ve already covered the “Alternate Page with Proper Canonical Tag” issue in detail, but it’s worth noting that Google Search Console (GSC) often flags other related indexing and canonicalization problems.
In this section, I’ll briefly walk you through a few of these common related errors you might encounter in your GSC report. The good news? Most of them can be resolved using the same principles we’ve discussed earlier
So, let’s dive into these related issues and clear up any confusion, one error at a time.
You might also be interested in how to solve a similar issue, “Crawled – currently not indexed” in GSC.

The ‘Duplicate, Google Chose Different Canonical Than User’ issue in Google Search Console (GSC) means that Google has found multiple pages with similar content, and instead of using the canonical URL you specified, it decided to index a different version it considers more appropriate.
Yes, sometimes there might be inconsistencies between your declared canonical tag, internal links, and sitemap entries.
💡 Conflicting Signals: There might be inconsistencies between your declared canonical tag, internal links, and sitemap entries.
💡 Content Similarity: Google may detect the same content across different URLs and decide the one you marked as canonical isn’t the best choice.
💡 Improper Redirects: If your site has redirect loops or improperly set up redirects, Google may favor another URL.
Page Signals: The alternative URL might have stronger SEO signals, like more backlinks or better internal linking.
The “Duplicate without user-selected canonical” issue in GSC means that Google has detected multiple pages on your website with similar or identical content, but none of them have a canonical tag telling Google which version should be considered the primary one for indexing.
Why This Happens:
If you ignore the warning, search engines might struggle to understand which version of your page to index and rank. This can lead to duplicate content issues, where multiple versions of the same page compete against each other in search results.
However, if you’ve intentionally set up canonical URLs—for example, on paginated pages, localized content, or specific URL variants, it’s usually nothing to worry about. The warning is just a reminder to double-check that everything aligns with your intended strategy.
When you submit canonical fixes in Google Search Console (GSC), it typically takes a few days to a couple of weeks for Google to validate the changes. The timeline depends on factors like crawl frequency, the size of your website, and how often Google bot visits the affected pages.
For smaller websites, validation might happen faster, sometimes within a few days. However, on larger sites with thousands of URLs, it could take several weeks.
No, you should not have multiple canonical tags on one page. Google and other search engines expect a single canonical tag to clearly indicate the preferred version of the page. When multiple canonical tags are present, search engines may get confused, ignore them entirely, or pick one at random, which could undermine your SEO efforts.
If you’re trying to reference multiple URLs, you likely have an issue with your setup. Double-check your page’s source code and make sure only one rel=”canonical” tag is present, pointing to the most relevant, authoritative version of the page.
Yes, canonical tags can work across domains and subdomains, but they need to be implemented correctly to be effective. When you’re dealing with duplicate or highly similar content across different domains (e.g., example.com and example2.com) or subdomains (blog.example.com and shop.example.com), canonical tags tell search engines which version of the page should be treated as the primary one.
However, search engines treat cross-domain canonicals more as a strong suggestion rather than a directive.