
by: SEO Strategist
Ashot Nanayan
December 24, 2024
13 min read
WhatsApp
 (+1) 818 355 1889
(+1) 818 355 1889
WhatsApp
(+1) 818 355 1889
WhatsApp
(+1) 818 355 1889
WhatsApp
(+1) 818 355 1889
I know nobody likes seeing red flags in their Search Console dashboard, and the “Crawled – Currently Not Indexed” status is one of those messages that every website owner has encountered at some point.
But this message doesn’t mean your content is bad or your SEO efforts are pointless. It simply means Google saw your page, gave it a once-over, and decided, “Meh, not right now.” Ouch. But hey, Google’s not perfect either, and there’s almost always a logical reason behind this status.
In this blog post, I’ll break down exactly why this happens, how to diagnose the issue like an SEO pro, and most importantly, how to fix it. Don’t worry, I’ll keep things clear, actionable, and free from SEO jargon that makes you want to bang your head against the keyboard.

Ready to clean up that Search Console report and finally see your pages indexed? Let’s dive in.
So, Google Search Console is basically our translator between Google’s indexing system and us. It tells us two key things:
When you see “Crawled – Currently Not Indexed,” it means Google did visit your page. The bot walked through your digital hallways, noted everything down, and then for reasons only Google knows, decided not to add your page to its index right now.
On the other side, there’s another status: “Discovered – Currently Not Indexed.” This one’s different. It means Google knows your page exists (maybe through a sitemap or an internal link), but it hasn’t even taken the time to crawl it yet.
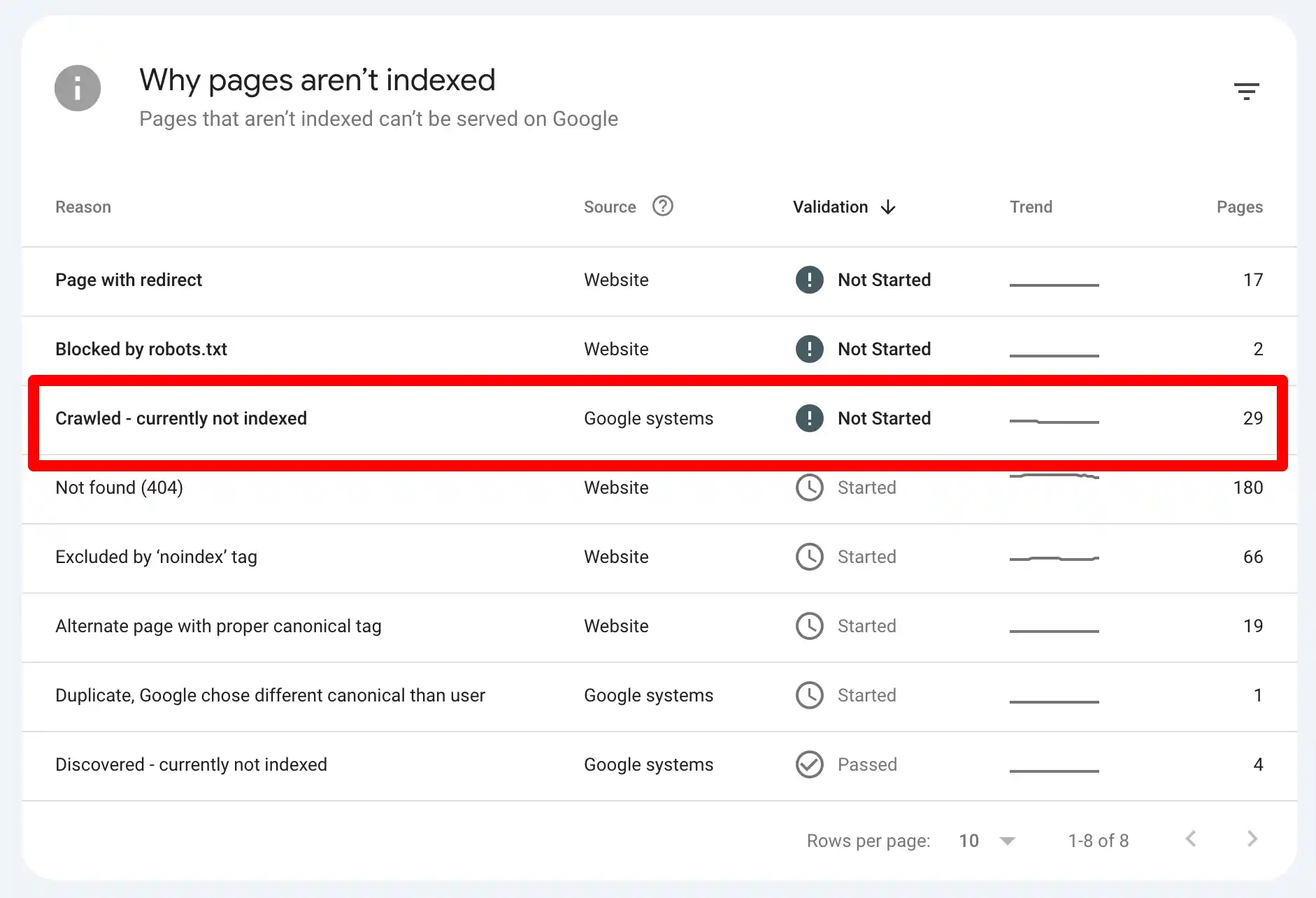
Alright, it depends.
Sometimes, it’s nothing. Google might just need time. Maybe your page is newer, or there’s a backlog in their system. If your website is relatively small (like under 500 pages), it’s often temporary.
But… if weeks go by and that status isn’t changing? Yeah, it’s time to investigate.
There are specific reasons why Google might choose not to index your content. The good news is that most of them have clear, actionable solutions.
So, let’s break it down. Below, I’m going to walk you through the most common reasons behind this issue, along with practical solutions you can apply to make sure your content finally gets the attention it deserves.

Alright, let’s talk, just you and me, writer to writer. Sometimes, it’s not the algorithm’s fault. Sometimes, it’s the content itself, and before you raise your eyebrows at me, let me break this down.
Spammy content isn’t just about keyword stuffing anymore. Sure, using the same keyword 15 times in a 500-word blog post is still a no-go.
But these days, spammy content is also about intent. Did you write this to really help someone, or did you put random paragraphs together just to trick Google? Search engines have gotten really good at spotting content written for machines, not humans.

For instance, thin affiliate posts, repetitive text that goes in circles, or those clickbait titles promising the moon but delivering… well, nothing.
Low-quality content doesn’t always look bad at first glance. But it’s like a beautifully wrapped gift wity; nothing inside. It lacks depth. It doesn’t answer the user’s question. Or worse, it answers it halfway and then leaves them hanging.
And then… there’s AI content without a human touch
Don’t get me wrong. I have nothing against AI content. But content crafted entirely by AI, without human review, without a heartbeat behind it is a problem.
You see, AI can put sentences together. It can mimic structure. But it doesn’t feel. It doesn’t pause for emphasis, it doesn’t make you think, and it definitely doesn’t leave you with that aha! moment.
Google knows this. If your content feels robotic, lacks a unique angle, or is just an AI regurgitation of what’s already out there, it’s probably not getting indexed.
Google prioritizes E.E.A.T., so AI-generated content without human oversight often lacks the depth, credibility, and personal insights needed to meet these quality standards and rank well.
So, if your content feels spammy, thin, or soulless, it’s not going to pass the gatekeepers of Google’s indexing systems.
Technical SEO issues are often a primary culprit. These are usually ignored, but they can prevent your pages from being properly crawled or indexed.
Let’s break down the most frequent technical SEO problems and how to fix them in no time.
A canonical tag tells search engines which version of a page is the “master” or preferred one when duplicate content exists. If implemented incorrectly, it can signal to Google that your page shouldn’t be indexed.

Here is an example of a correct canonical tag
How to identify the issue:
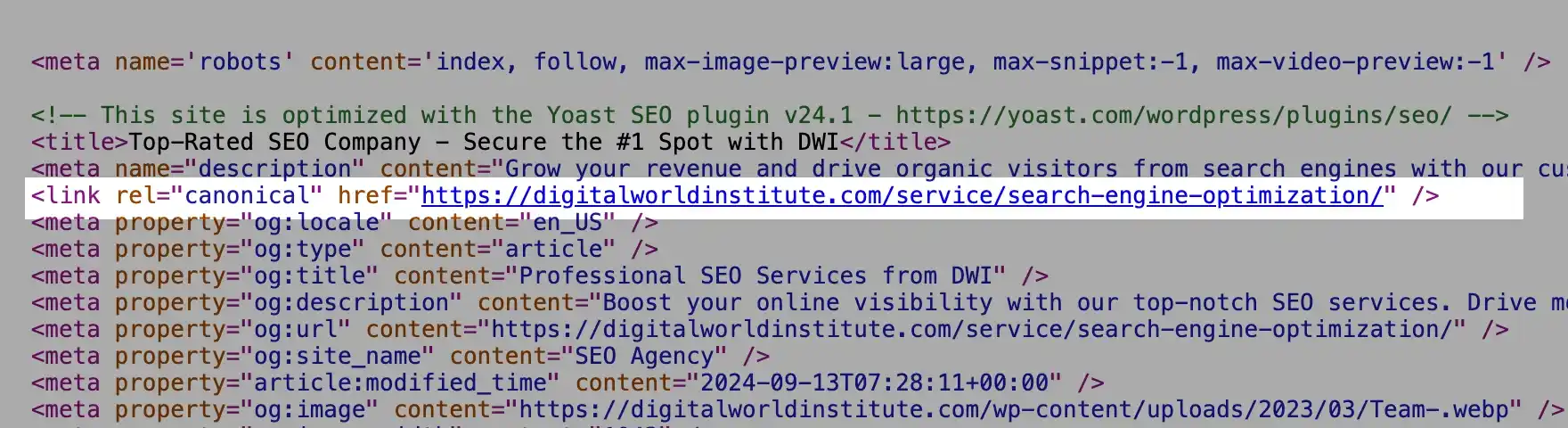
If this URL points to a different page unnecessarily, Google might skip indexing.
Solution:
The robots.txt file instructs search engine crawlers which pages they can or cannot access on your site.
Example of a blocking rule
In this example, all crawlers are instructed not to crawl any pages under /blog/.
How to Check Robots.txt:
Solution:
You can also use a robots.txt validator and testing tool to make sure your website’s robots.txt file isn’t accidentally blocking important pages from being indexed by search engines.
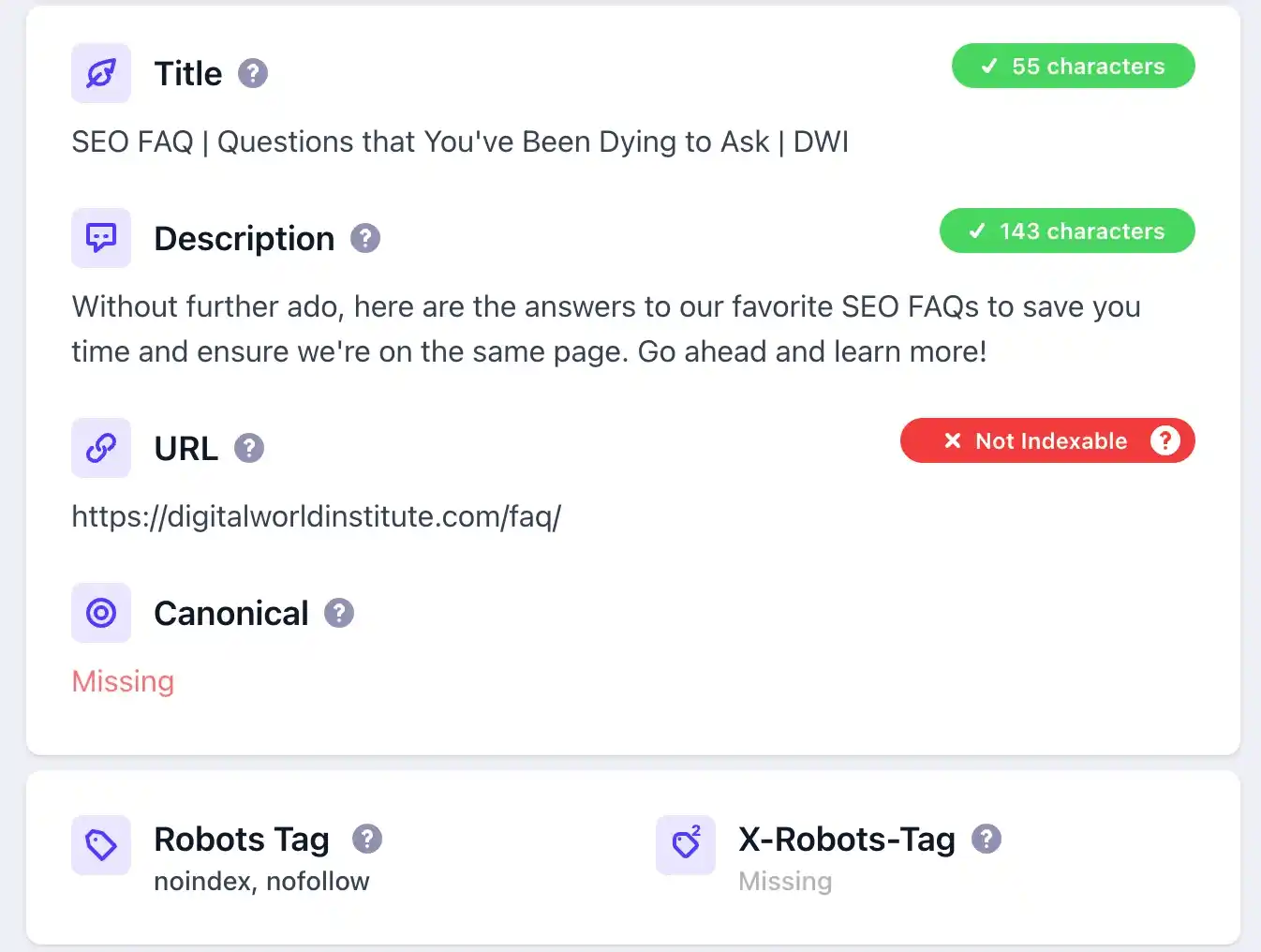
The meta noindex tag explicitly tells search engines not to index a page.
Example of an indexable page:
How to Find Meta Noindex Tags:
Solution:
Tip: Use tools like Screaming Frog to scan your site for pages with noindex tags.
You can also install a Chrome extension like the Detailed SEO Extension and quickly see what’s going on a specific page of your website (Example is below):
Google allocates a specific crawl budget to each site. If your site has poor internal linking or deep URL structures, some pages might not get crawled or indexed.
How to Check Internal Linking:
Solution:

Slow page speed or server errors can be a major reason why Google crawls your content but doesn’t index it. When Google bot attempts to access your page and encounters slow loading times or frequent server errors (e.g., 5xx status codes), it may abandon the crawling or indexing process altogether.
Yes, my friend – Google may skip indexing if your page takes too long to load or if your server frequently times out.
Google allocates a specific “crawl budget” to each website. Slow pages consume more of this budget, reducing the number of pages Google bot can crawl in one session.
Here you can find what pages Google prioritizes most and where you spend your crawl budget:
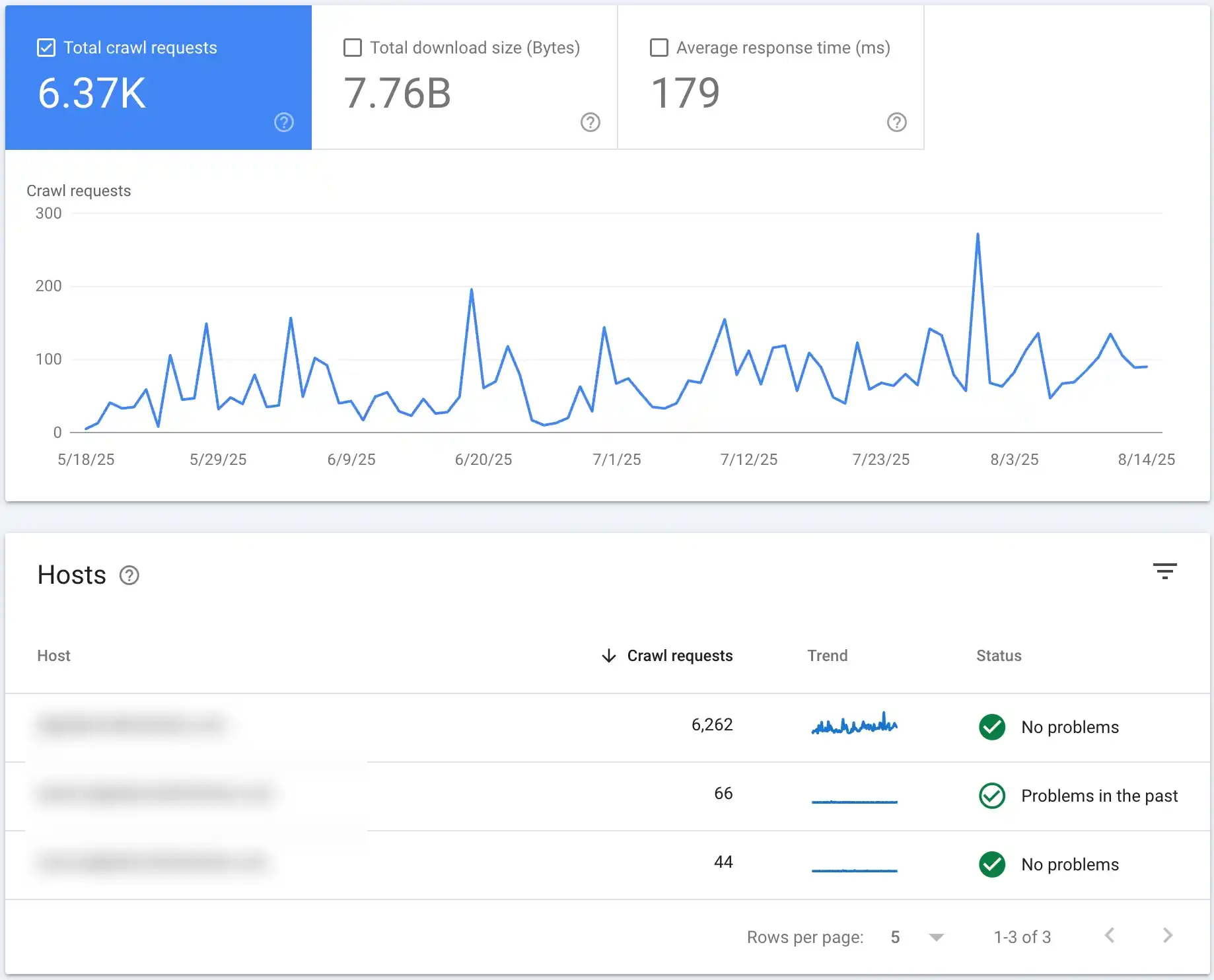
On the other hand, server errors prevent Google bot from properly accessing and understanding your content, making indexing impossible.
You can use Google PageSpeed Insights or GTmetrix to measure your site’s speed. Then, consult with your developer to optimize your website speed (e.g., enable caching, and compress images).
Additionally, make sure your hosting server can handle your site’s traffic, regularly monitor server logs for errors, and fix recurring issues promptly.
If indexing issues are your current headache, you might also be interested in learning how to fix the ‘Alternate page with proper canonical tag’ error in Google Search Console, since it often goes hand in hand with broader indexing problems.

If your XML sitemap isn’t properly configured, Google might fail to discover or index some of your pages, especially if they’re buried deep within your website structure. However, on smaller websites (under 500 pages), this is rarely a critical issue.
Google’s crawlers are pretty efficient at navigating simple site structures and following internal links to find content naturally.
But as your website grows in size and complexity, a well-structured XML sitemap becomes less of a luxury and more of a necessity.

For smaller sites, most pages are just a click or two away from the homepage, and internal linking usually does enough of the heavy lifting for search engines to find your content.
In these cases, even if your sitemap is slightly misconfigured or missing a few URLs, Google will likely still discover and index your important pages through standard crawling. But if your site has isolated content silos, orphan pages, or inconsistent internal linking, then even smaller sites can experience indexing gaps.
On larger websites, especially those with thousands of pages, dynamic content, or eCommerce platforms with products coming and going, the XML sitemap becomes crucial.
When the sitemap isn’t configured properly, Google might:
In short, the bigger your site, the more critical a properly optimized XML sitemap becomes.
Different CMS platforms like WordPress, Shopify, or Magento handle XML sitemaps differently, and each comes with its own set of benefits and limitations:
WordPress: Plugins like Yoast SEO or Rank Math generate XML sitemaps automatically, but misconfigurations (e.g., excluding certain content types) can cause indexing issues.
Magento: Sitemaps often require fine-tuning, especially for product pages, categories, and dynamically generated URLs.
Shopify: It automatically generates an XML sitemap, but large catalogs can result in fragmented or incomplete sitemaps.
If you’re seeing indexing issues, it’s worth consulting your developer or technical SEO agency to review how your sitemap is being generated and whether it aligns with Google’s best practices.
Webflow: It automatically generates an XML sitemap and updates it when you publish new pages. However, one limitation is that you don’t have as much granular control as with WordPress plugins or Magento configurations.
For example, excluding certain pages or customizing priority settings requires manual adjustments, often through project settings or custom code.
Common XML Sitemap Mistakes to Watch Out For
I would highly recommend checking the “Sitemaps” section for errors or warnings. You can use XML Sitemap Validator or Screaming Frog to make sure it meets Google’s requirements. If you’re on platforms like Magento or WordPress, make sure plugins or built-in tools are configured correctly.
From my experience as an SEO expert, I’ve noticed a recurring issue that often goes overlooked: Programmatic SEO can seriously impact how Google crawls and indexes your pages.
When your site is new and you suddenly add hundreds of thousands of pages, usually city pages, product variations, or dynamically generated content, it raises red flags for Google. These pages often have near-duplicate content, with only minor differences like city names, product SKUs, or localized descriptions.
As I already explained, Google allocates a limited crawl budget to every website based on its authority, relevance, and perceived quality. When a flood of similar pages suddenly appears, Google may decide to stop crawling new pages until it’s confident they provide value.
If these programmatically generated pages lack unique content or meaningful differentiation, Google might categorize them as low-value content or even as potential spam.
Instead of launching tens of thousands of pages at once, focus on publishing smaller batches of your highest-value pages. Let Google crawl and index these successfully before scaling up. Even for programmatically generated pages, make sure each page has enough unique value. Add localized details, specific data points, or user-generated content (e.g., reviews) to set them apart.
Patience is Key: Programmatic SEO isn’t an overnight success story. Google needs time to trust your site, understand your structure, and evaluate content quality. Resist the urge to panic or make sudden changes after only a few weeks.
Sometimes the simplest solutions solve the biggest SEO problems. I believe it’s easy to get caught up in complex technical SEO audits, endless optimization tips, and deep-dive analytics to figure out why certain pages aren’t being indexed. But sometimes, the solution is staring right at you, and it’s shockingly simple.
One of the most overlooked, yet incredibly effective, methods to make sure your pages get indexed is by using Google Search Console’s “Request Indexing” feature. it’s an official tool provided by Google and often fixes indexing problems faster than you’d expect.
“Request Indexing” is a feature within Google Search Console that allows website owners and SEO professionals to manually ask Google to crawl and index a specific page or URL. This tool becomes incredibly handy when you’ve just published a new page, made significant updates to an existing one, or noticed that a critical page isn’t showing up in search results.
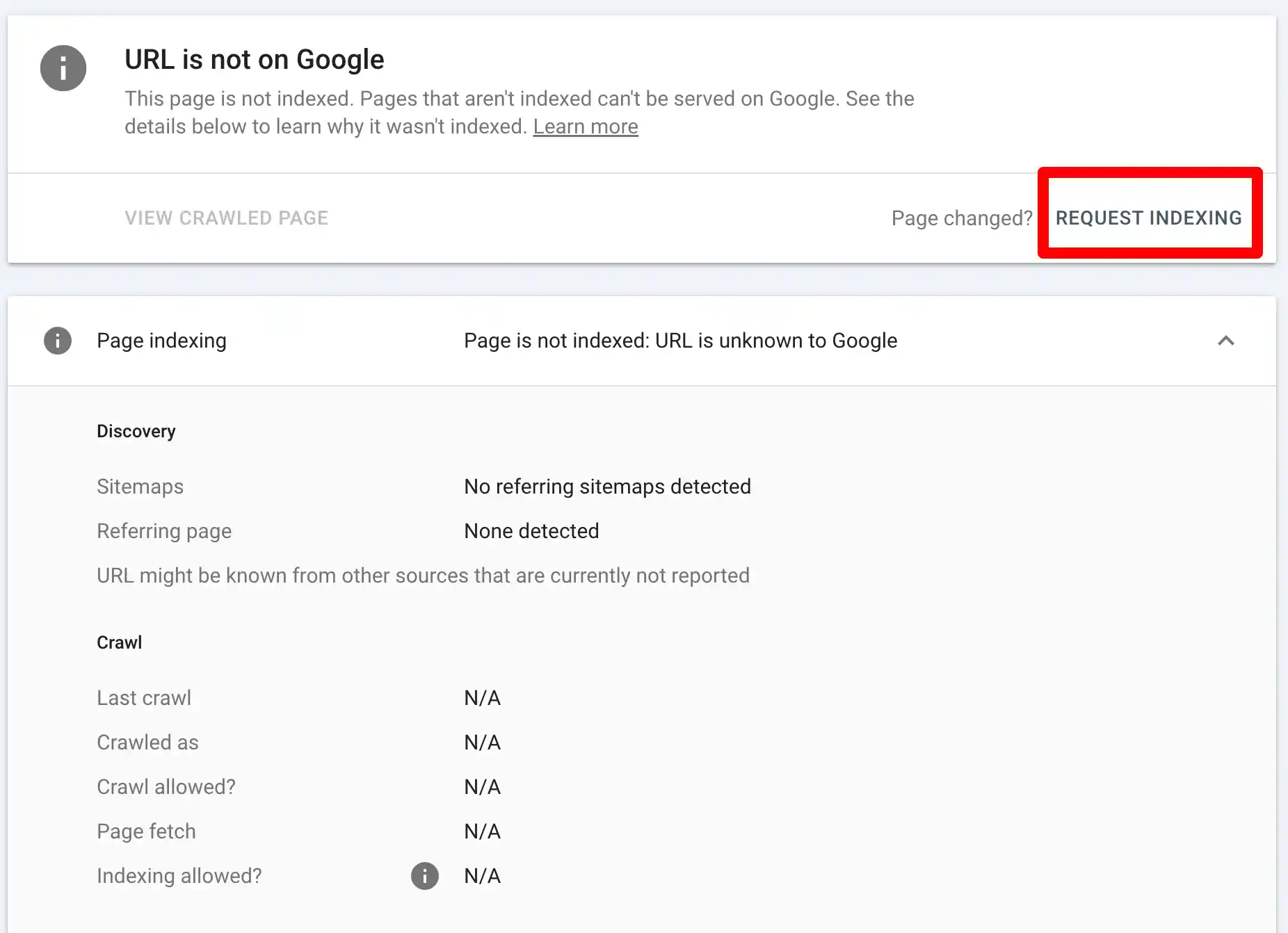
Essentially, it’s like raising your hand in a crowded room and saying, “Hey Google, over here! Take a look at this page.”
Immediate Action is Rare: Don’t expect your page to appear in search results instantly. Google usually prioritizes indexing requested URLs but it might still take anywhere from a few minutes to a couple of days.
No Guaranteed Indexing: Remember, requesting indexing is not a guarantee your page will be indexed, it simply tells Google to take another look.
Follow-Up Required: If your page still isn’t indexed after a reasonable wait, deeper technical issues might be at play (e.g., canonical errors, duplicate content, or poor-quality content).
If you notice your pages aren’t getting indexed after some time, don’t panic, it’s a common issue, especially for new websites. Google tends to prioritize indexing pages from sites with established authority and trust.
Search engines have limited resources for crawling and indexing, so they prioritize authoritative domains with strong backlink profiles and proven relevance in their niche. If your site lacks these signals, it might sit in the queue for a while or worse, get overlooked altogether.
In my comprehensive guide on link-building for newbies, I’ve already said that backlinks are one of the most important ranking factors in search engine optimization. The more high-quality sites link back to your content, the more trustworthy and authoritative your site appears. So, invest in different link-building techniques like guest posting, HARO outreach, or niche edits.

Don’t rely on a single tactic. Diversify your approach with a mix of editorial links, resource page placements, and digital PR campaigns to create a natural-looking backlink profile.
Search engines love content hubs; clusters of well-researched, interlinked articles around a single topic. Create pillar content supported by detailed subtopics. Show Google you’re not just publishing isolated pages but building a comprehensive knowledge base.
Make it easy for crawlers to discover your important pages by ensuring a strong internal linking structure. Every key page should have relevant internal links from other high-authority pages on your site. Google prefers fresh and valuable content. Keep your content updated, review your on-page SEO, and address keyword gaps to increase visibility.
If none of the earlier points address your specific situation, don’t worry, you’re not out of options just yet. There are still some advanced actions you can take to fix the ‘Crawled – Currently Not Indexed’ issue in the Google Search Console.
These steps go beyond the basics and require a more strategic approach, but they can often uncover hidden problems or provide the push needed to get your pages indexed. Let’s dive into these next-level solutions.
Sometimes, even when everything seems perfect: solid content, technical SEO checks, proper meta tags, and no obvious errors, a webpage still refuses to get indexed. In such cases, log file analysis becomes your secret weapon.
So, what is log file analysis? Every time a search engine crawler visits your website, it leaves behind a digital footprint in your server logs. Log File Analysis is the process of examining these server logs to understand exactly how search engines interact with your site.
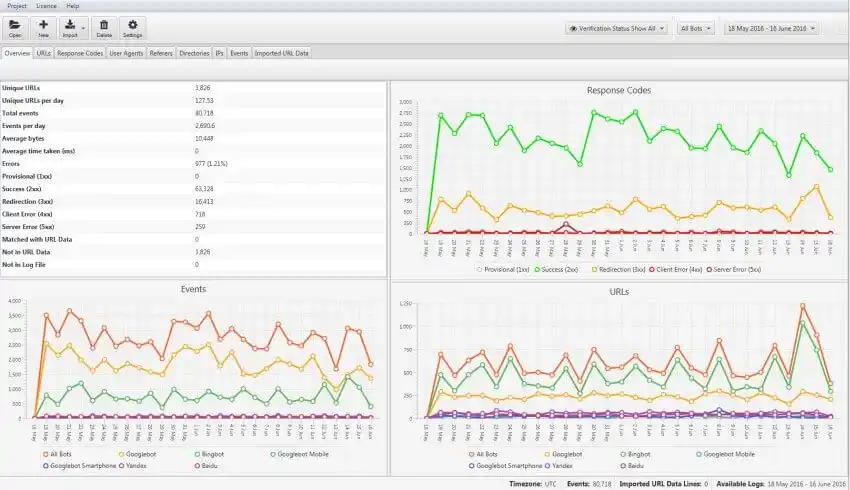
You can see which pages search engine bots are visiting and how frequently. Identify if bots are spending too much time on unimportant pages instead of crawling your key content.
Detect if important URLs are unintentionally blocked by robots.txt or have HTTP errors or spot redirect loops or unnecessary redirect hops that might be confusing crawlers.
Log file analysis gives you raw, unfiltered data directly from your server. It removes the guesswork and shows you exactly how Google bot or Bing bot interacts with your site. For example, you might discover that your problematic page is being crawled frequently but flagged as “low priority” due to poor internal linking, or it’s stuck in a redirect loop.
In short, when traditional SEO checks fail to explain indexing issues, log file analysis lets you step into the crawler’s shoes and see what’s happening behind the scenes. It’s a technical but incredibly powerful method to diagnose and fix indexing roadblocks.
If you want to get your web pages indexed faster, I advise you to use tools like Sinbyte, which uses the Google Indexing API. Instead of waiting for Google’s bots to eventually crawl and index your pages, these tools send a direct request to Google, essentially saying, ‘Hey, this page is fresh, come check it out now!
The Google Indexing API is an official tool provided by Google, primarily for websites that frequently update or publish time-sensitive content, like news sites or job postings. It allows webmasters to instantly notify Google about new or updated content, skipping the traditional waiting game of organic crawling.
Yes, Google indexing API was initially promoted for news and job-related websites but it works for general websites as well. Whether you’re publishing blog posts, product pages, or landing pages, using the API won’t cause penalties or violate Google’s guidelines. In fact, it’s an approved method to speed up indexing and make sure your content doesn’t get lost in the shuffle.
In short, Sinbyte and similar tools using the Google Indexing API aren’t just for news giants, they’re valuable for any website owner looking to keep their content fresh, visible, and competitive in search results. If you’re serious about SEO, integrating tools like these into your workflow is a smart move.
In Google Search Console, when you see the status “Crawled – Currently Not Indexed,” you might notice some unusual URLs, often containing symbols like “?” or other query parameters. These URLs typically appear on eCommerce websites or platforms with filtering and sorting options (e.g., color filters, size filters, or sorting by price). You might also see them from pagination pages like /page/2, or dynamic URLs generated by search functions.

Now, here’s the key point: not every unindexed page is a problem. If these URLs are correctly canonicalized (pointing to the primary version of the page using a canonical tag), they’re essentially telling Google, “Hey, we know this URL exists, but the real focus is on the main version.” In this case, Google is doing its job by ignoring duplicate or low-value pages to keep its index clean.
For example, an eCommerce site might have a product page URL like:
/products/shoes?color=red&size=9
If this page has a canonical tag pointing back to the primary product page (/products/shoes), you’re in good shape. Google understands that the canonical version holds valuable content.
The real issue arises when:
But if everything is correctly set up, you can safely ignore these URLs in the “Crawled – Currently Not Indexed” report. These pages aren’t harming your SEO, and trying to remove them from the report would be a waste of time.
Instead, focus your energy on indexing high-value pages like category pages, product pages, and blog content. In short: if the canonicalization is correct, and these URLs are just parameter-based or pagination-related, let Google handle them; they’re not worth losing sleep over.
The time it takes for Google to index your website after fixing an issue reported in Google Search Console (GSC) can vary. In most cases, it ranges from a few days to a few weeks. If you’ve clicked the “Validate Fix” button in GSC, Google prioritizes re-crawling those specific pages.
For smaller sites or less complex issues (like fixing broken links or meta tags), you might see results within 3-7 days. For larger websites or more significant changes (e.g., resolving coverage errors or large-scale content updates), it can take 2-4 weeks or longer for the fixes to fully reflect in search results.
Factors like crawl budget, site authority, and Google bot’s crawling frequency on your site also play a role. To speed things up, ensure your sitemap is updated, your internal links are well-structured, and the fixed pages are easily accessible for Google bot. Patience is key, but consistently monitoring your Index Coverage Report in GSC will give you a clearer picture of progress.
To check if a specific page is indexed by Google, simply go to Google Search and type:
If the page appears in the search results, it’s indexed. If not, it might still be crawling or could have indexing issues. For a more detailed check, you can use Google Search Console:
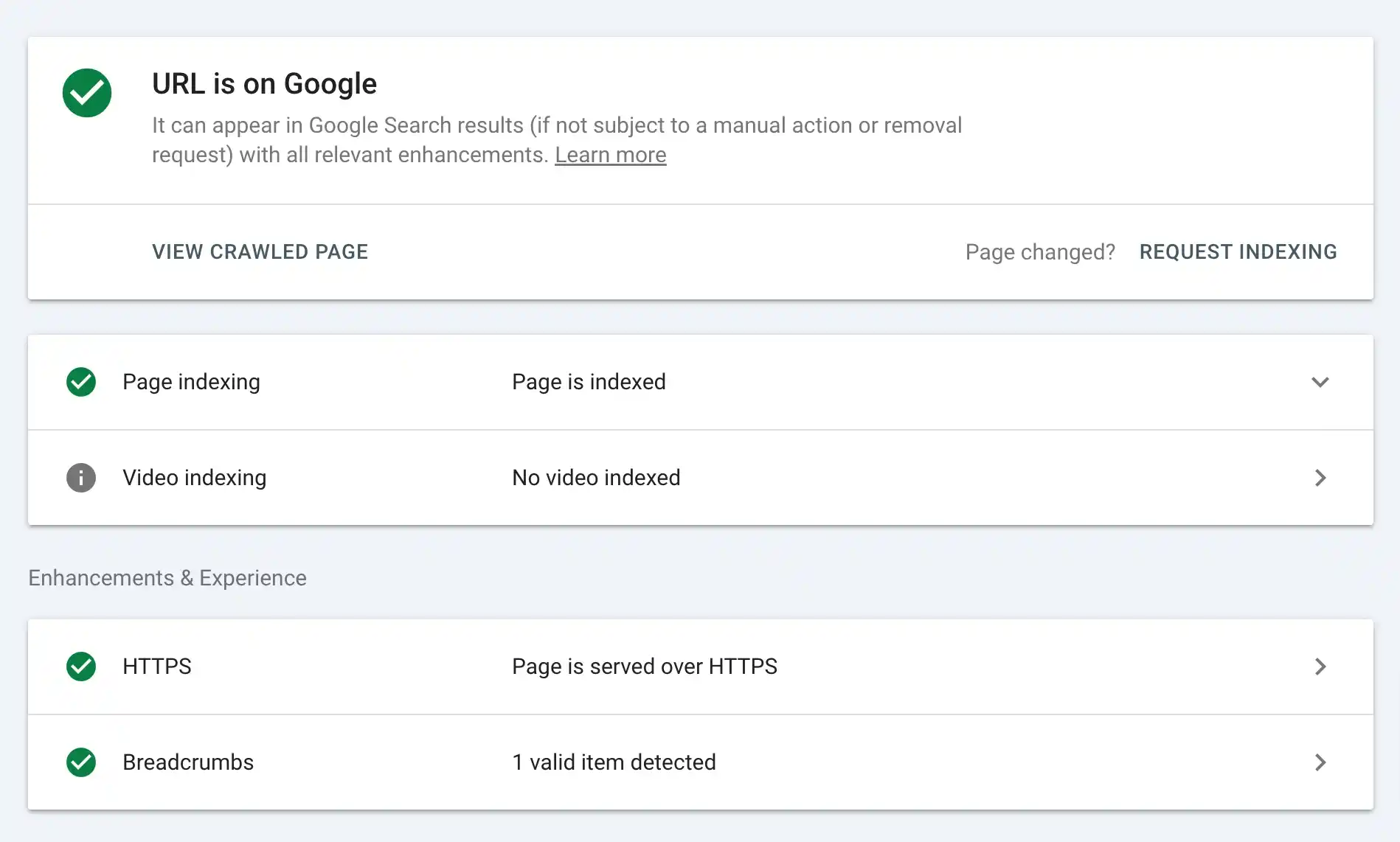
This method is quick, reliable, and gives you a clear picture of your page’s indexing status.